dedup
| This command implementation is limited |
Definition
dedup removes rows that has identical values for selected columns. With optional arguments, you can define how or how many duplicate values are kept or how they are sorted.
|
Currently, |
Syntax
| dedup <interger> <column-name> [keepevents=<boolean>] [keepempty=<boolean>] [consecutive=<boolean>] [sortby (+ | -) (<column-name> | auto(<column-name) | ip(<column-name>) | num(<column-name>) | str(<column-name>))]Examples
You can remove duplicate row values from columns with dedup.
The simplest dedup query can contain only the table column’s name. The following example cuts results approximately to a half.
index=crud earliest=-5y
| dedup _raw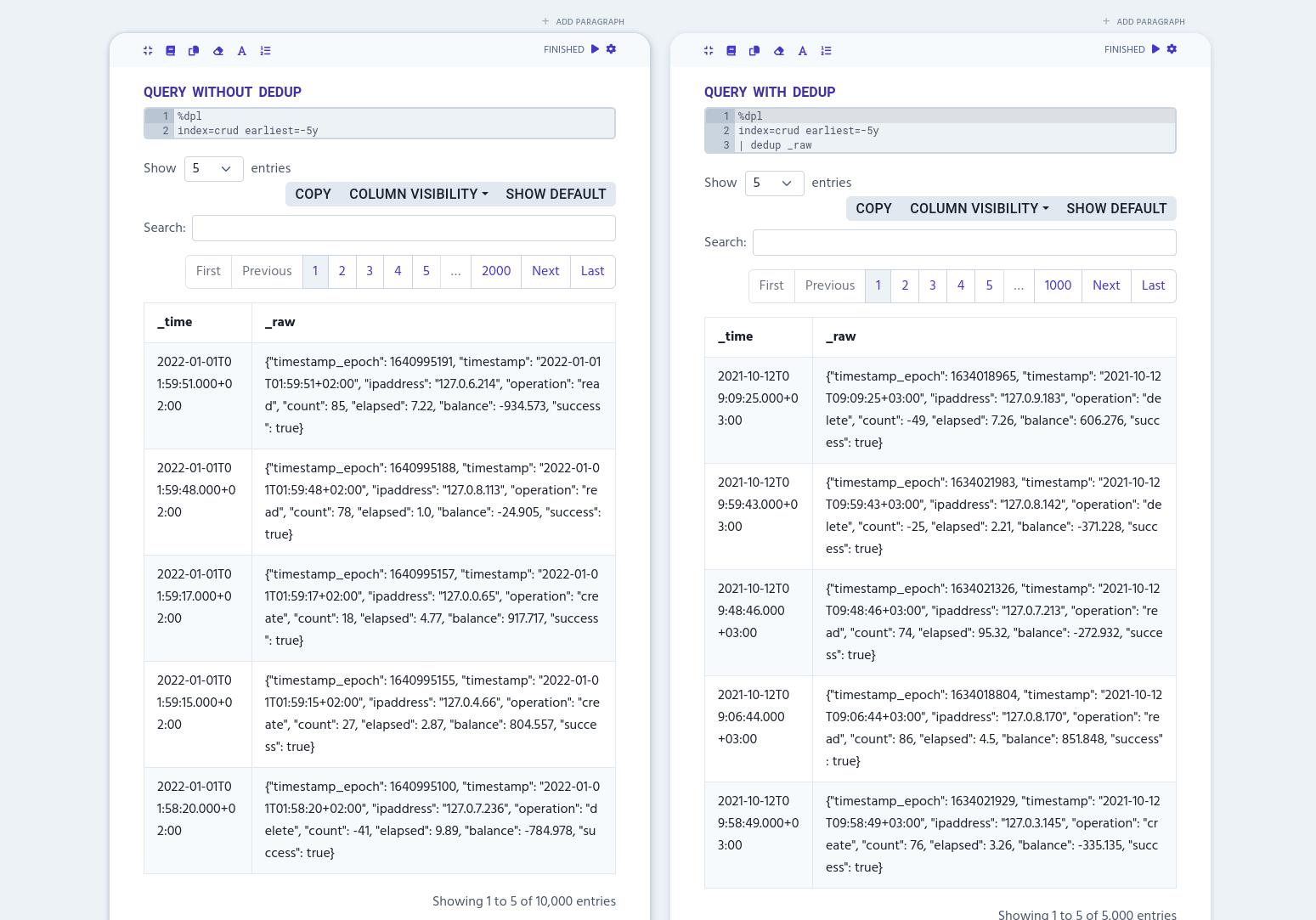
You can also remove duplicate values based on more than one column.
%dpl
index=crud earliest=-5y
| spath
| dedup elapsed count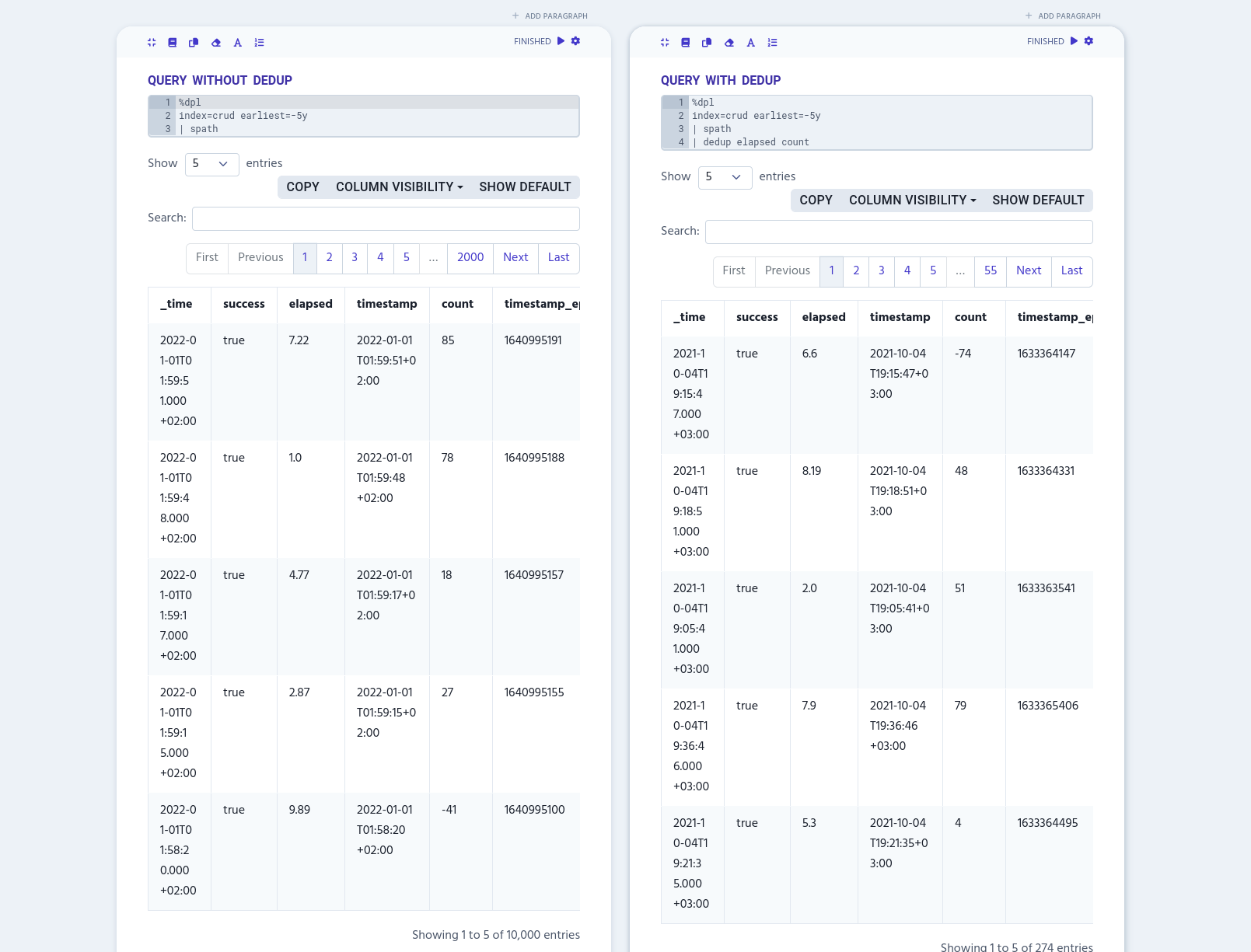
Keep multiple duplicated rows
| Not yet implemented. |
You can define how many duplicated rows dedup keeps in results by giving a numerical value before the column’s name. The following example keeps three duplicated rows.
consecutive
| Not yet implemented. |
Use consecutive to keep or remove consecutive duplicated combinations of values. It’s set to false by default.
keepempty
| Not yet implemented. |
Use keepempty argument with dedup to show rows that have NULL values. It’s set to false by default.