Administrator Guide
Administrator guide requires that the reader is already familiar with how to use Teragrep. Experience in the field of analytical programming is also needed.
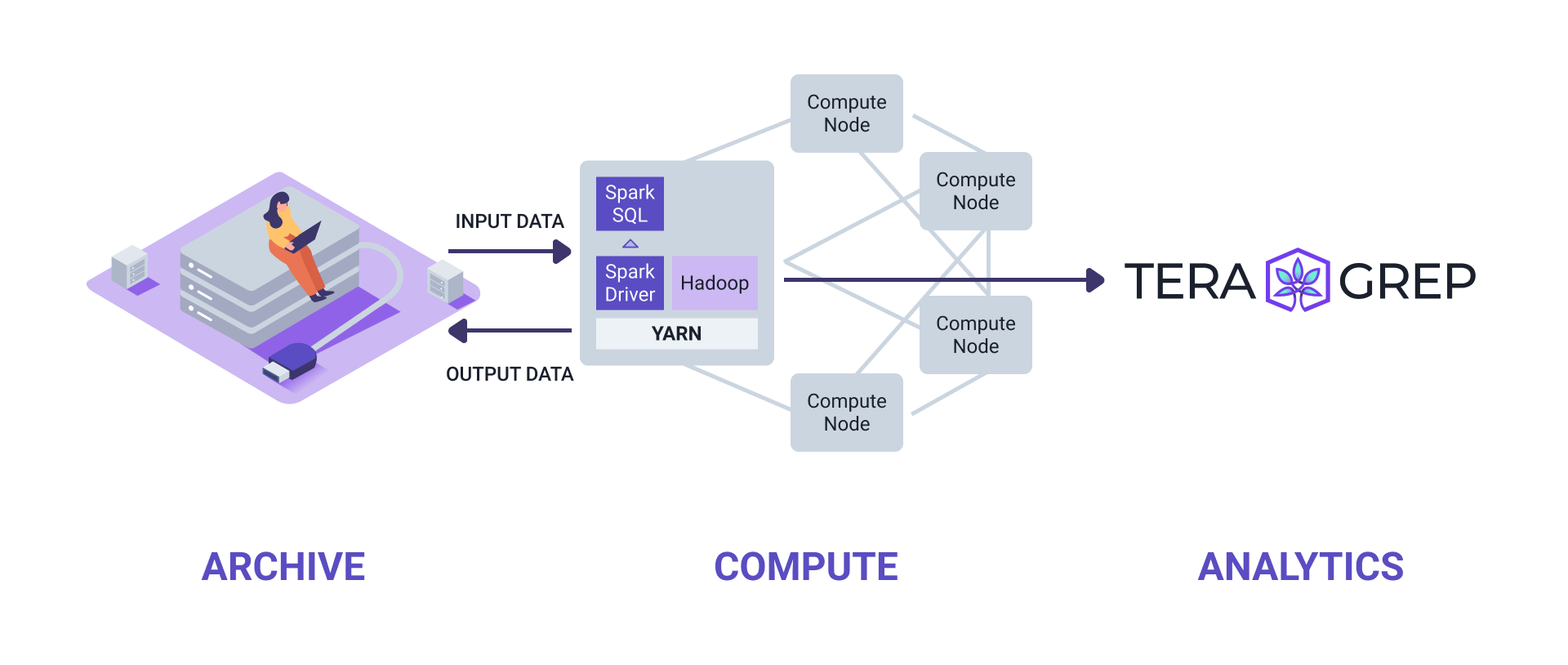
This section enables the user to use advanced data processing features and to program using Apache Spark. More in-depth documentation for Apache Spark can be found here.
About Teragrep
Teragrep is built on the Apache Spark technology, and it uses Apache Zeppelin for interacting with Spark.
The language used by Teragrep is called the Data Processing Language (DPL). DPL has a native integration to the Teragrep Archive, so the user can intuitively search through and process the archived data. Implementing a total custom solution is also possible: all the processing flow elements are exposed for use in custom solutions, and they do not require the use of DPL.
| Please note that the coverage and scale of DPL are far from final, and compatibility issues with other products using the same language do currently exist. Teragrep advices you to submit found issues to Teragrep’s Github. |
License
Teragrep is licensed under GNU Affero General Public License with additional permissions and supplemented terms, which are detailed here.