Dashboard with Scala and PySpark
The following steps outline how to create a dynamic input form in PySpark interpreter.
Create Input with Scala
Let’s create first an input which allows us to search data by the year.
We need to use z.input() and z.angularBind() to make this happen. z.input() function creates the input and z.angularBind() function creates the universal variable. The latter function works only in Spark interpreter, which is the reason why we’re going to use Scala only with this input.
Add the following to the first paragraph in your notebook:
%spark
z.angularBind("year",z.input("Year"))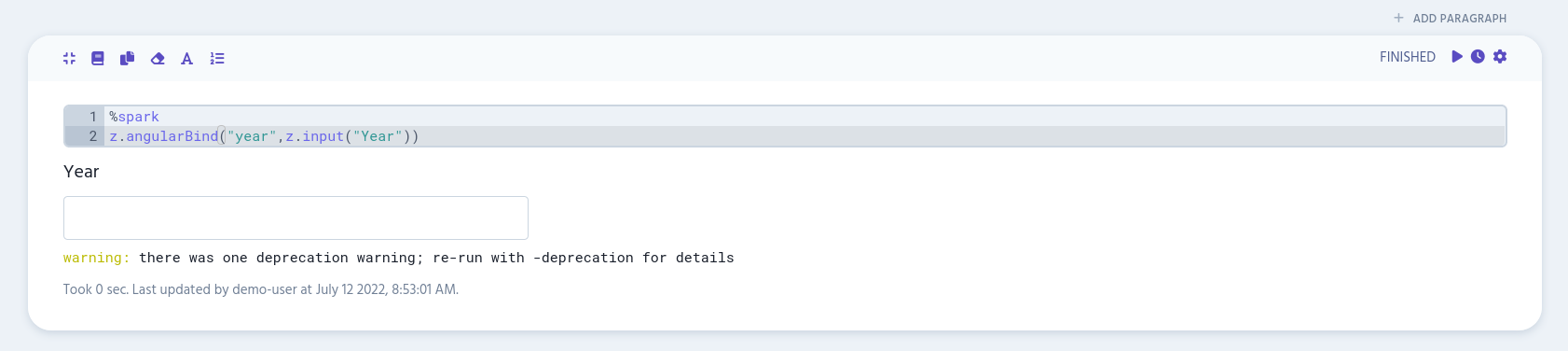
At this point, this input won’t do anything, since it’s not connected to any program flow. We need to do that next.
Create a Program Flow
Let’s create a table with some useful data, so we can do searches with our Scala input.
First, we create a new paragraph and add the following to the editor:
%pyspark
from pyspark.sql.functions import *
from pyspark.sql.types import *
import getpassThese will import collections of built-in functions which we’re going to use.
Now we need to add the streaming completion check method to the same editor:
def isArchiveDone(streaming_query):
archive_done = True
print(streaming_query.lastProgress)
for datasource in streaming_query.lastProgress["sources"]:
start_offset = datasource["startOffset"]
end_offset = datasource["endOffset"]
description = datasource["description"]
if description is not None and not description.startswith("com.teragrep.pth06.ArchiveMicroBatchReader@"):
# ignore others than archive
pass
if start_offset is not None:
if not start_offset == end_offset:
archive_done = False
else:
archive_done = False
return archive_doneThis will check if the streaming is complete and will be used later to terminate the streaming.
Then we add spark_session and spark_context:
spark_session = spark.builder.getOrCreate()
spark_context = spark_session.sparkContextAfter that, we add StructType and StructField classes:
# collect data from all columns
Schema = StructType([
StructField("_time", TimestampType(), True),
StructField("_raw", StringType(), True),
StructField("directory", StringType(), True),
StructField("stream", StringType(), True),
StructField("host", StringType(), True),
StructField("input", StringType(), True),
StructField("partition", StringType(), False),
StructField("offset", LongType(), True),
StructField("origin", StringType(), True)])With StructType and StructField classes, we’re going to collect data from the following columns:
-
_time,
-
_raw,
-
directory,
-
stream,
-
host,
-
input,
-
partition,
-
offset, and
-
origin
In addition, we’ll define their data type and whether they’re nullable or not.
Then we set credentials and the passage for the user:
s3identity = getpass.getuser()
s3credential = None
try:
path = "hdfs:///user/" + s3identity + "/s3credential"
df = spark_context.textFile(path)
s3credential = df.first()
except:
print("Unable to get s3credential from HDFS")
exit(1)Depending on what program flow you’re using, you might need to alter this part.
Then we create the streaming data frame:
# streaming DataFrame
df = spark_session.readStream.schema(Schema).format("com.teragrep.pth06.ArchiveSourceProvider") \
.option("S3endPoint", spark_context.getConf().get("fs.s3a.endpoint")) \
.option("S3identity", s3identity) \
.option("S3credential", s3credential) \
.option("DBusername", spark_context.getConf().get("dpl.archive.db.username")) \
.option("DBpassword", spark_context.getConf().get("dpl.archive.db.password")) \
.option("DBurl", spark_context.getConf().get("dpl.archive.db.url")) \
.option("DBstreamdbname", spark_context.getConf().get("dpl.archive.db.streamdb.name")) \
.option("DBjournaldbname", spark_context.getConf().get("dpl.archive.db.journaldb.name")) \
.option("num_partitions", "1") \
.option("queryXML", """<index value="f17_mini" operation="EQUALS"/>""") \
.load()After that, we structure the incoming data:
df1 = df.withColumn("new_field", regexp_extract(df._raw, r"(\"[r|R]ainfall\w+[^,]*)", 0))
df2 = df1.withColumn("rainfall_rate", regexp_extract(df1.new_field, r"(\d.*)", 0))\
.withColumn("year", year("_time"))
# create an SQL temporary view
df2.createOrReplaceTempView('Table')
# Filter the data in the table based on the value(s) in the dynamic form
df3 = spark.sql("""SELECT * FROM Table
WHERE year = """ + z.angular("year") + """
""")
# Group results by year
df4 = df3.groupBy("year").count()Basically, we’re going to select all rows where the year is the same as the Scala input value, count the results and then group them by the year.
And as a last step, we add the streaming query which updates the display every second:
#streaming query
query = df4.writeStream.trigger(processingTime="1 milliseconds")\
.format("memory")\
.outputMode("complete")\
.queryName("streamingTest")\
.start()
# update display every second
while not query.awaitTermination(1):
# use zeppelin context "z" to render the output
z.getInterpreterContext().out().clear(True)
z.show(spark_session.sql("SELECT * FROM streamingTest"))
if query.lastProgress is not None and isArchiveDone(query) == True:
query.stop()Now we’re ready to run the paragraph. The result looks like this:
%pyspark
from pyspark.sql.functions import *
from pyspark.sql.types import *
import getpass
def isArchiveDone(streaming_query):
archive_done = True
print(streaming_query.lastProgress)
for datasource in streaming_query.lastProgress["sources"]:
start_offset = datasource["startOffset"]
end_offset = datasource["endOffset"]
description = datasource["description"]
if description is not None and not description.startswith("com.teragrep.pth06.ArchiveMicroBatchReader@"):
# ignore others than archive
pass
if start_offset is not None:
if not start_offset == end_offset:
archive_done = False
else:
archive_done = False
return archive_done
spark_session = spark.builder.getOrCreate()
spark_context = spark_session.sparkContext
Schema = StructType([StructField("_time", TimestampType(), True),
StructField("_raw", StringType(), True),
StructField("directory", StringType(), True),
StructField("stream", StringType(), True),
StructField("host", StringType(), True),
StructField("input", StringType(), True),
StructField("partition", StringType(), False),
StructField("offset", LongType(), True),
StructField("origin", StringType(), True)])
s3identity = getpass.getuser()
s3credential = None
try:
path = "hdfs:///user/" + s3identity + "/s3credential"
df = spark_context.textFile(path)
s3credential = df.first()
except:
print("Unable to get s3credential from HDFS")
exit(1)
df = spark_session.readStream.schema(Schema).format("com.teragrep.pth06.ArchiveSourceProvider") \
.option("S3endPoint", spark_context.getConf().get("fs.s3a.endpoint")) \
.option("S3identity", s3identity) \
.option("S3credential", s3credential) \
.option("DBusername", spark_context.getConf().get("dpl.archive.db.username")) \
.option("DBpassword", spark_context.getConf().get("dpl.archive.db.password")) \
.option("DBurl", spark_context.getConf().get("dpl.archive.db.url")) \
.option("DBstreamdbname", spark_context.getConf().get("dpl.archive.db.streamdb.name")) \
.option("DBjournaldbname", spark_context.getConf().get("dpl.archive.db.journaldb.name")) \
.option("num_partitions", "1") \
.option("queryXML", """<index value="f17_mini" operation="EQUALS"/>""") \
.load()
df1 = df.withColumn("new_field", regexp_extract(df._raw, r"(\"[r|R]ainfall\w+[^,]*)", 0))
df2 = df1.withColumn("rainfall_rate", regexp_extract(df1.new_field, r"(\d.*)", 0))\
.withColumn("year", year("_time"))
df2.createOrReplaceTempView('Table')
df3 = spark.sql("""SELECT * FROM Table
WHERE year = """ + z.angular("year") + """
""")
df4 = df3.groupBy("year").count()
query = df4.writeStream.trigger(processingTime="1 milliseconds")\
.format("memory")\
.outputMode("complete")\
.queryName("streamingTest")\
.start()
# update display every second
while not query.awaitTermination(1):
# use zeppelin context "z" to render the output
z.getInterpreterContext().out().clear(True)
z.show(spark_session.sql("SELECT * FROM streamingTest"))
if query.lastProgress is not None and isArchiveDone(query) == True:
query.stop()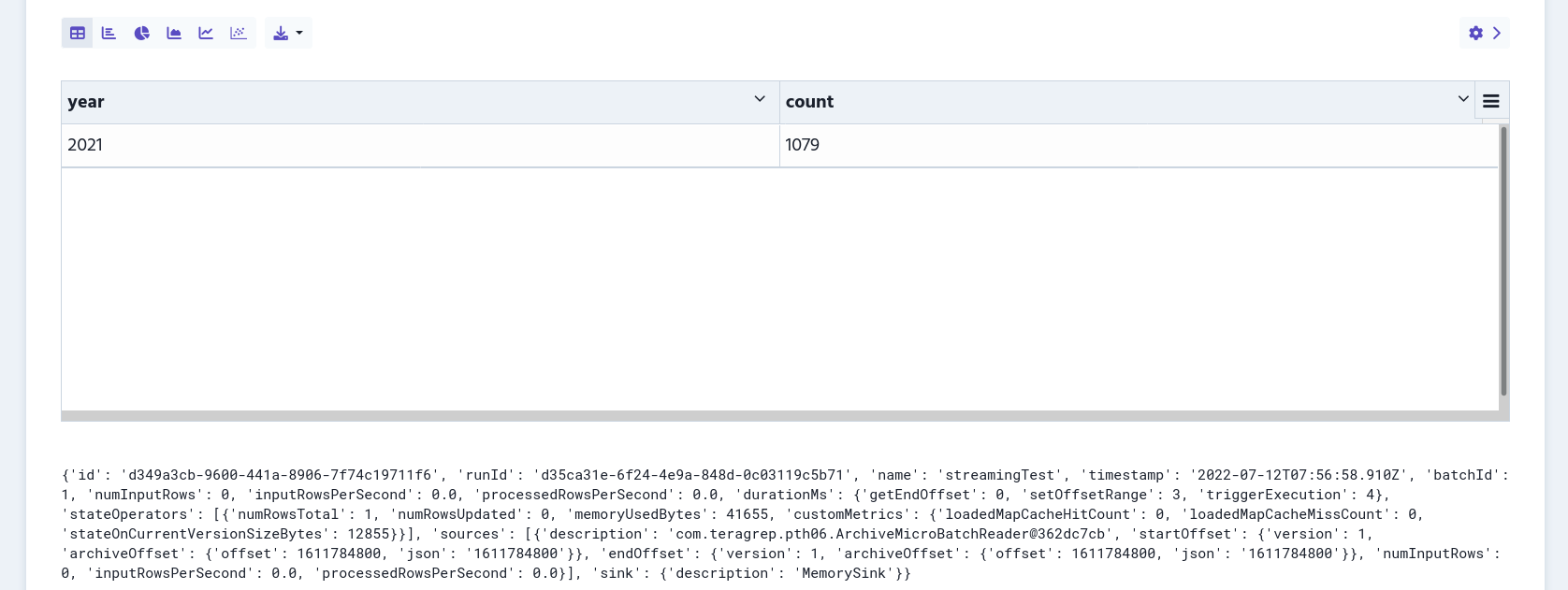
Now we need to connect the table and the Scala input.
Connect the Program Flow with the Scala Input
To connect the program flow with the Scala input we created in the first step, we need to add the program flow’s paragraph ID to the first paragraph. This can be done with z.run() function.
Copy the program flow’s paragraph ID and add it to the first paragraph’s editor after the Scala input code:
%spark
z.angularBind("year",z.input("Year"))
// run other paragraphs everytime the value in field changes
z.run("your-paragraph-id")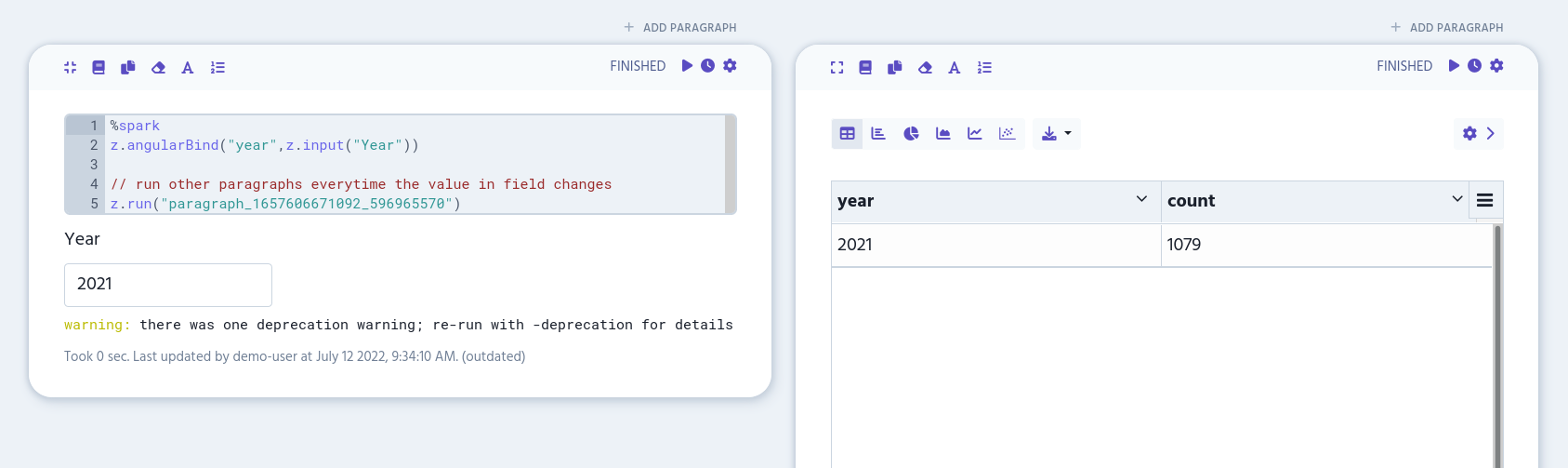
Now you have a working form input, ready for the action. You can connect the same Scala input to another program flows at the same time as well. Use the z.run() function and fetch the correct paragraph IDs for it.
%spark
z.angularBind("year",z.input("Year"))
// run other paragraphs everytime the value in field changes
z.run("first-paragraph-id")
z.run("second-paragraph-id")
z.run("third-paragraph-id")