Languages
Teragrep uses an Apache Zeppelin feature called Zeppelin Interpreters to implement different language back-ends. These language back-ends are categorized into interpreter groups.
Interpreters within the same group can share data between each other. For example, you can perform a search using DPL, and then further process the results using Scala, as they both belong to the Spark group of interpreters.
To choose an interpreter, enter a percent sign (%) followed by the interpreter name in the paragraph’s code editor.
| The credentials accessible with the code snippets used in documentation examples are public information. They do not grant access to protected resources, but only to non-sensitive information. |
The interpreter may crash if a programming error has been made. To restart it, click the reload icon in the interpreter binding settings.
To configure interpreters, read more here.
Data Flow
Teragrep takes user input using paragraphs in the notebook view. When a notebook is created, it is stored as a new file on a Git repository. New notebooks are created with a single paragraph.
Select the desired interpreter in the paragraph’s code editor. If the interpreter belongs to the Apache Spark group, the code is then packaged and launched within Apache Spark. If not, the code is compiled and executed directly. Results of the execution are then pushed back to the Teragrep user interface, which processes the received output and displays it on the output section of the paragraph.
DPL abstracts the complexity of the tasks required to access the Teragrep Archive.
The code is executed using the user’s credentials. Because of this, the program receives the same user level permissions that the user has on the operating system that is running Teragrep, and the operating system logging mechanism (such as SELinux) records a log of all the operations.
Interpreter Dependencies
Teragrep can download dependencies when configured with a remote Maven Repository.
For more information, see Apache Zeppelin’s documentation.
For security reasons, dynamic dependency loading is currently not shipped with Teragrep. However, dependencies can be configured for each interpreter individually.
Standalone Interpreters
Standalone interpreters are interpreters that don’t belong to any group with other interpreters. Because of this, they can’t share data between other interpreters in memory. They can still access files within the file system, of course.
| You can use the standalone interpreters to demonstrate different code snippets within your organization. You can combine this with the Maven Dependency feature, which can download Maven artifacts from your organization’s internal repository. This is a handy way of working when using DevOps practices. |
Display Systems
Teragrep uses AngularJS to render output.
Angular can be used as an interpreter either in front-end mode or in back-end mode. In front-end mode the browser code controls the execution; in back-end mode, other interpreters are allowed to modify the displayed content.
You can use the front-end mode by using %angular at the start of paragraph editor.
%angular
<h1>Angular Example</h1>
<div class="col-4">
<div class="input-group mb-3">
<input type="text" placeholder="Write something here" class="form-control" />
<button class="btn btn-secondary">Send</button>
</div>
</div>
<h2>Sub Title</h2>
<p>You can use HTML elements to create your own dashboards.</p>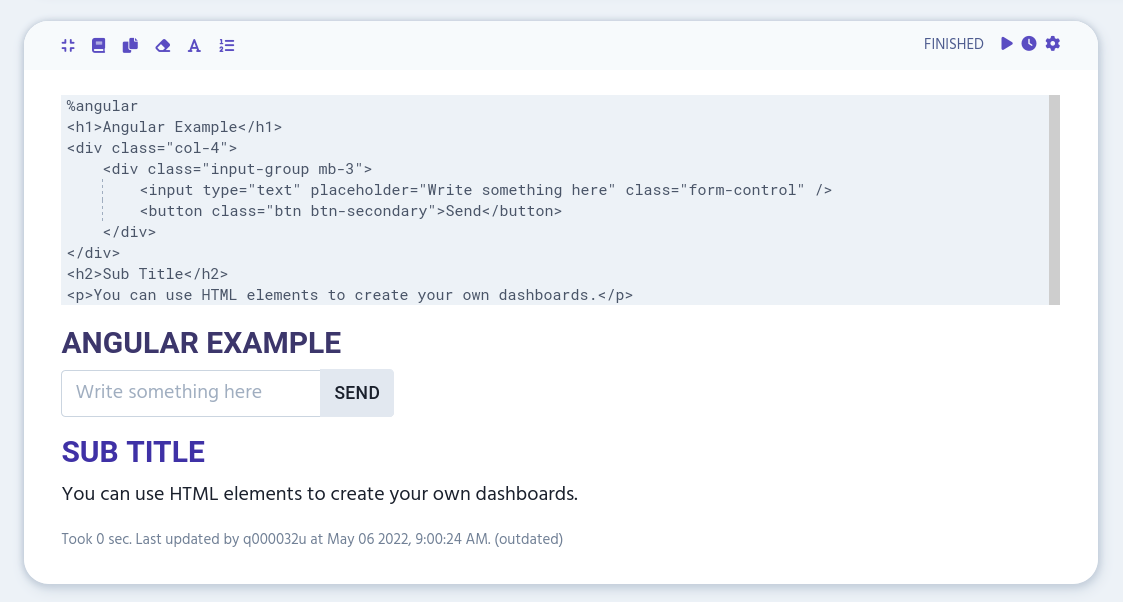
With %angular you can use HTML elements to create your own dashboards. Use Bootstrap to style your angular output.
You can use the back-end mode by printing out standard output strings that begin with %angular:
%sh
echo '%angular <h1>Hey</h1>'