Scala
Table of Contents
| Work in process |
Scala is the default language for Apache Spark. Because of this, Scala is selected by entering %spark on the paragraph’s code editor.
%spark
println(sc.version)
println(util.Properties.versionString)
println(java.net.InetAddress.getLocalHost().getHostName())
println(System.getProperty("user.name"))
println(java.time.LocalDateTime.now.format(java.time.format.DateTimeFormatter.ofPattern("dd.MM.yyyy hh:mm:ss")))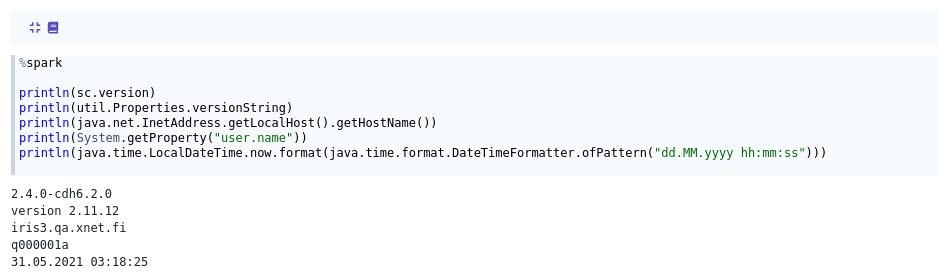
Archive Access
Scala can be used to access the Teragrep Archive by using the following code:
%spark
import org.apache.spark.SparkConf // for accessing properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.streaming.Trigger
import java.sql.Timestamp
import org.apache.spark.sql.streaming.StreamingQuery
private def isArchiveDone(streamingQuery: StreamingQuery) = {
var archiveDone = true
for (i <- streamingQuery.lastProgress.sources.indices) {
val startOffset = streamingQuery.lastProgress.sources(i).startOffset
val endOffset = streamingQuery.lastProgress.sources(i).endOffset
val description = streamingQuery.lastProgress.sources(i).description
if (description != null && description.startsWith("com.teragrep.pth06.ArchiveMicroBatchReader@")) { // ignore others than archive
if (startOffset != null) {
if (startOffset != endOffset) {
archiveDone = false
}
}
else {
archiveDone = false
}
}
}
archiveDone
}
val s3identity: String = System.getProperty("user.name")
var s3credential: String = _
try {
val path: String = "hdfs:///user/" + s3identity + "/s3credential";
val df = spark.read.textFile(path);
s3credential = df.first()
}
catch {
case e: Exception => {
println("Unable to get s3credential from HDFS: " + e)
System.exit(1)
}
}
val df = spark
.readStream
.format("com.teragrep.pth06.ArchiveSourceProvider")
.option("S3endPoint", sc.getConf.get("fs.s3a.endpoint"))
.option("S3identity", s3identity)
.option("S3credential", s3credential)
.option("DBusername", sc.getConf.get("dpl.archive.db.username"))
.option("DBpassword", sc.getConf.get("dpl.archive.db.password"))
.option("DBurl", sc.getConf.get("dpl.archive.db.url"))
.option("DBstreamdbname", sc.getConf.get("dpl.archive.db.streamdb.name"))
.option("DBjournaldbname", sc.getConf.get("dpl.archive.db.journaldb.name"))
.option("num_partitions", "1")
.option("queryXML", """<index value="f17" operation="EQUALS"/>""")
.load()
val df2 = df.agg(count($"_time").as("count"))
val query = df2
.writeStream
.outputMode("complete")
.format("memory")
.trigger(Trigger.ProcessingTime(0))
.queryName("ArchiveAccessExample")
.start()
while (!query.awaitTermination(1000)) {
val dfOut = sqlContext.sql("SELECT * FROM ArchiveAccessExample")
z.getInterpreterContext.out.clear(true);
z.show(dfOut)
if(query.lastProgress != null && isArchiveDone(query))
query.stop()
}
s3credential="" // clear so it's not present on the output