Pyspark
Table of Contents
| Work in process |
In Teragrep, PySpark is part of Spark interpreter group.
To use PySpark in Teragrep’s editor, write %spark.pyspark or %pyspark at the start.
%pyspark
import sys
import datetime
import socket
import getpass
import numpy
print(sys.version)
print(numpy)
print(socket.gethostname())
print(getpass.getuser())
print(datetime.datetime.now())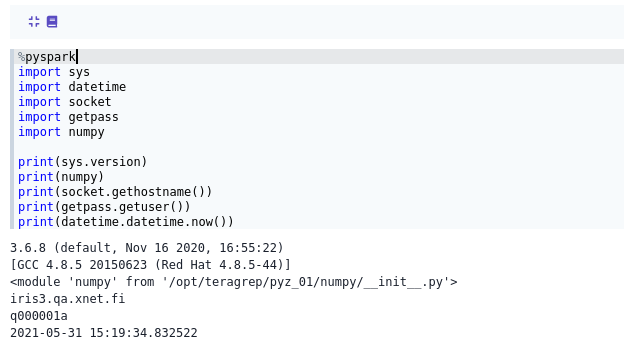
Archive Access
PySpark can be used to access the Teragrep Archive by using the following code:
%pyspark
from pyspark.sql.functions import *
from pyspark.sql.types import *
import getpass
def isArchiveDone(streaming_query):
archive_done = True
print(streaming_query.lastProgress)
for datasource in streaming_query.lastProgress["sources"]:
start_offset = datasource["startOffset"]
end_offset = datasource["endOffset"]
description = datasource["description"]
if description is not None and not description.startswith("com.teragrep.pth06.ArchiveMicroBatchReader@"):
# ignore others than archive
pass
if start_offset is not None:
if not start_offset == end_offset:
archive_done = False
else:
archive_done = False
return archive_done
spark_session = spark.builder.getOrCreate()
spark_context = spark_session.sparkContext
Schema = StructType([StructField("_time", TimestampType(), True),
StructField("_raw", StringType(), True),
StructField("directory", StringType(), True),
StructField("stream", StringType(), True),
StructField("host", StringType(), True),
StructField("input", StringType(), True),
StructField("partition", StringType(), False),
StructField("offset", LongType(), True)])
s3identity = getpass.getuser()
s3credential = None
try:
path = "hdfs:///user/" + s3identity + "/s3credential"
df = spark_context.textFile(path)
s3credential = df.first()
except:
print("Unable to get s3credential from HDFS")
exit(1)
df = spark_session.readStream.schema(Schema).format("com.teragrep.pth06.ArchiveSourceProvider") \
.option("S3endPoint", spark_context.getConf().get("fs.s3a.endpoint")) \
.option("S3identity", s3identity) \
.option("S3credential", s3credential) \
.option("DBusername", spark_context.getConf().get("dpl.archive.db.username")) \
.option("DBpassword", spark_context.getConf().get("dpl.archive.db.password")) \
.option("DBurl", spark_context.getConf().get("dpl.archive.db.url")) \
.option("DBstreamdbname", spark_context.getConf().get("dpl.archive.db.streamdb.name")) \
.option("DBjournaldbname", spark_context.getConf().get("dpl.archive.db.journaldb.name")) \
.option("num_partitions", "1") \
.option("queryXML", """<index value="f17" operation="EQUALS"/>""") \
.load()
df2 = df.agg(count(col("_time")))
query = df2.writeStream.trigger(processingTime="0 seconds").outputMode("complete").format("memory").queryName(
"PySparkExample").start()
# update display every second
while not query.awaitTermination(1):
# use zeppelin context "z" to render the output
z.getInterpreterContext().out().clear(True)
z.show(spark_session.sql("SELECT * FROM PySparkExample"))
if query.lastProgress is not None and isArchiveDone(query) == True:
query.stop()Dynamic Forms
You can use PySpark to create dynamic forms programmatically.